
Von Marc Karl
Es sind nicht immer die aufwendigsten Architekturen oder ausgeklügelten Frameworks, die den größten Unterschied machen. Oft liegt die Stärke in der Einfachheit – in klaren, modularen Strukturen, die in der Praxis zuverlässig und effizient funktionieren.
In diesem Artikel teile ich meine persönlichen Erfahrungen aus der täglichen Arbeit mit KI-Agenten. Ich zeige auf, welche Muster sich bewährt haben, wann sich der Einsatz von Agenten lohnt – und wann nicht – und worauf es bei der Umsetzung wirklich ankommt.
Inhaltsverzeichnis
- Was genau sind eigentlich AgenteBlogn?
- Wann lohnt sich ein Agent – und wann lieber nicht?
- Frameworks: Nützlich, aber mit Vorsicht genießen
- Bewährte Muster aus der Praxis
- Grundbaustein: Das augmentierte LLM
- Workflow: Prompt Chaining
- Workflow: Routing
- Workflow: Parallelisierung
- Workflow: Orchestrator-Worker
- Workflow: Evaluator-Optimizer
- Autonome Agenten – flexibel, leistungsfähig, aber mit Verantwortung
- Zusammenfassung und Fazit
Was genau sind eigentlich Agenten?
Der Begriff „Agent“ wird ganz unterschiedlich interpretiert – und das zu Recht. Manche sprechen von Agenten, wenn sie vollständig autonome Systeme meinen, die über längere Zeiträume hinweg eigenständig arbeiten, Tools nutzen und komplexe Aufgaben Schritt für Schritt selbst lösen. Andere wiederum verwenden den Begriff für stärker strukturierte Systeme, die klar vordefinierten Abläufen folgen.
Alle diese Varianten zählen wir zu den agentischen Systemen, aber es ist essenziell, architektonisch zwischen zwei Kategorien zu unterscheiden:
- Workflows: Hier orchestrieren wir LLMs und Tools entlang fester, vordefinierter Pfade im Code. Die Entscheidungslogik liegt größtenteils im Systemdesign.
- Agenten: Hier übernehmen die LLMs selbst die Regie. Sie entscheiden dynamisch, wie sie Aufgaben angehen, welche Tools sie wann einsetzen und wie sie mit dem Feedback aus ihrer Umgebung umgehen.
Beide Ansätze haben ihre Berechtigung – und ihre Stärken. In der Praxis kommt es darauf an, den richtigen Typus für die jeweilige Aufgabenstellung zu wählen. Im weiteren Verlauf werde ich beide Arten agentischer Systeme näher beleuchten.
Unter dem Punkt „Agenten in der Praxis“ beschreibe ich außerdem zwei konkrete Anwendungsfelder, in denen ich gemeinsam mit Mitarbeitern besonders viel Mehrwert durch agentische Systeme erzielen konnte.
Wann lohnt sich ein Agent – und wann lieber nicht?
Nicht jedes Problem braucht gleich ein agentisches System – und das ist auch gut so. In der Praxis zeigt sich immer wieder: Die beste Lösung ist häufig die einfachste. Erst wenn sich klare Vorteile abzeichnen, sollte man die Komplexität schrittweise erhöhen.
Agentische Systeme sind mächtig, aber sie kommen auch mit einem Preis: Sie tauschen oft Latenz und Rechenkosten gegen höhere Flexibilität und Aufgabenleistung ein. Ob sich dieser Trade-off lohnt, hängt ganz vom Anwendungsfall ab – und sollte sorgfältig bewertet werden.
Wenn der Anwendungsfall klar strukturiert ist und die Anforderungen stabil bleiben, empfehle ich in der Regel den Einsatz klassischer Workflows. Sie liefern Vorhersagbarkeit und konsistente Ergebnisse.
Braucht es jedoch mehr Entscheidungsfreiheit, dynamische Pfade oder modellgetriebene Prozesssteuerung – etwa bei hochvariablen Aufgaben in großem Maßstab – dann sind Agenten das Mittel der Wahl.
Für viele Anwendungen reicht allerdings bereits eine gut optimierte Einzelabfrage mit Retrieval und passenden Beispielen im Kontext. Das ist oft kosteneffizienter, schneller und vollkommen ausreichend.
Mein Fazit: Agenten sind kein Selbstzweck. Sie entfalten ihr volles Potenzial nur dann, wenn die Anforderungen nach Flexibilität, Selbststeuerung und Kontextverarbeitung wirklich da sind – und wenn man sie mit Bedacht einsetzt.
Frameworks: Nützlich, aber mit Vorsicht genießen
In der Praxis gibt es mittlerweile eine Vielzahl an Frameworks, die den Einstieg in agentische Systeme deutlich vereinfachen. Zu den bekanntesten zählen:
- LangGraph von LangChain
- Amazon Bedrock’s, AI Agent Framework
- Rivet, ein visuelles Drag-and-Drop-Tool für LLM-Workflows
- Vellum, ein weiteres GUI-Tool zur Erstellung und zum Testen komplexer Abläufe
- N8N, Workflowautomatisierung
Diese Frameworks nehmen einem viele standardisierte Aufgaben ab: LLMs aufrufen, Tools definieren und parsen, Aufrufe miteinander verketten – all das geht damit wesentlich schneller. Gerade in frühen Phasen eines Projekts oder zum Prototyping können sie sehr nützlich sein.
Aber: Aus meiner Erfahrung bringen diese Frameworks auch Schattenseiten mit sich. Sie schaffen zusätzliche Abstraktionsebenen, die schnell dazu führen, dass man den Überblick über die tatsächlichen Prompts und Modellantworten verliert. Das macht Debugging schwieriger und verschleiert oft, wie das System „wirklich denkt“.
Außerdem verleiten viele dieser Tools dazu, unnötige Komplexität aufzubauen – einfach, weil es so leicht geht. Aber: Nur weil man etwas umsetzen kann, heißt das nicht, dass man es auch tun sollte.
Mein Rat an Entwicklerinnen und Entwickler:
Startet – wann immer möglich – direkt mit der API des Modells. Viele Muster lassen sich mit wenigen Zeilen Code umsetzen, ohne dass man dafür ein Framework benötigt. Und wenn ein Framework doch zum Einsatz kommt, dann bitte nur mit fundiertem Verständnis für den zugrunde liegenden Code.
Fehlannahmen darüber, was „unter der Haube“ passiert, gehören zu den häufigsten Fehlerquellen in Projekten mit KI-Agenten.
Bewährte Muster aus der Praxis
In diesem Abschnitt möchte ich die häufigsten Muster und Strukturen teilen, die sich in realen Projekten mit agentischen Systemen bewährt haben. Diese Erkenntnisse stammen aus konkreten Implementierungen in produktiven Umgebungen – keine Theorie, sondern Erfahrungswerte aus dem Alltag.
Wir beginnen mit dem grundlegenden Baustein, dem augmentierten LLM, also einem Sprachmodell, das mit zusätzlicher Funktionalität wie Retrieval, Tools oder Memory erweitert wurde. Von dort aus steigern wir schrittweise die Komplexität – über einfache, klar strukturierte Workflows bis hin zu vollständig autonomen Agenten.
Ziel ist es nicht, möglichst komplexe Systeme zu bauen, sondern: die passende Lösung für die jeweilige Aufgabe zu finden – effizient, nachvollziehbar und wartbar.
Jedes dieser Muster hat seinen Platz, wenn man weiß, wann es sinnvoll ist und worauf man bei der Umsetzung achten muss.
Grundbaustein: Das augmentierte LLM
Beim Aufbau agentischer Systeme in Unternehmen bildet ein gezielt erweitertes – also augmentiertes – LLM für mich die zentrale Grundlage. Dieses Element ist das Herzstück nahezu aller erfolgreichen Agentensysteme, die ich in der Praxis kennengelernt habe.
Was bedeutet „augmentiert“ konkret?
Das Modell wird mit zusätzlichen Fähigkeiten ausgestattet, z. B.:
- Retrieval, also die Fähigkeit, externe Informationen aus Datenbanken oder Dokumenten abzurufen
- Tools, über die das Modell aktiv mit APIs oder Systemen interagieren kann
- Memory, um sich Informationen über den Verlauf einer Interaktion hinweg zu merken
Moderne Modelle können mit diesen Erweiterungen eigenständig arbeiten: Sie formulieren ihre eigenen Suchanfragen, wählen passende Tools aus und entscheiden, welche Informationen für den weiteren Verlauf relevant bleiben.
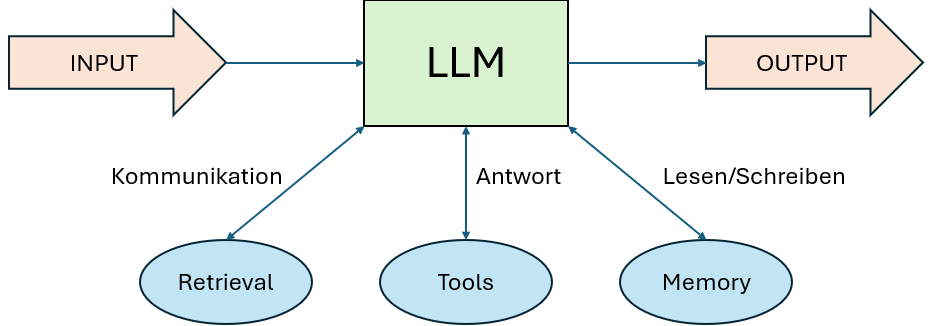
Worauf es in der Umsetzung ankommt
Aus meiner Sicht gibt es zwei zentrale Erfolgsfaktoren bei der Implementierung augmentierter LLMs:
- Die Erweiterungen müssen präzise auf den jeweiligen Anwendungsfall zugeschnitten sein. Es bringt wenig, dem Modell Zugriff auf zehn Tools zu geben, wenn es eigentlich nur zwei wirklich braucht – und diese nicht versteht.
- Die Schnittstelle zwischen Modell und Tooling muss klar, einfach und gut dokumentiert sein. Das ist die Grundlage dafür, dass das Modell mit den Erweiterungen auch tatsächlich effektiv arbeiten kann.
Ein bewährter Ansatz ist das sogenannte Model Context Protocol – damit lässt sich mit geringem Aufwand eine Verbindung zu einem wachsenden Ökosystem von Drittanbieter-Tools herstellen. In mehreren Projekten haben wir damit schnelle, saubere Integrationen umgesetzt.
Im weiteren Verlauf betrachte ich das augmentierte LLM als gegebenen Standard. Denn erst durch die Integration von Werkzeugen, Abrufmechanismen und Kontextspeicherung wird aus einem Sprachmodell ein wirklich handlungsfähiger Agent.
1. Workflow: Prompt Chaining
In vielen meiner Projekte hat sich Prompt Chaining als ein äußerst wirkungsvolles Muster bewährt – vor allem dann, wenn Aufgaben klar in Einzelschritte unterteilt werden können. Die Grundidee dahinter: Die Aufgabe wird sequenziell verarbeitet, wobei jeder LLM-Aufruf auf dem Ergebnis des vorherigen Schritts aufbaut.
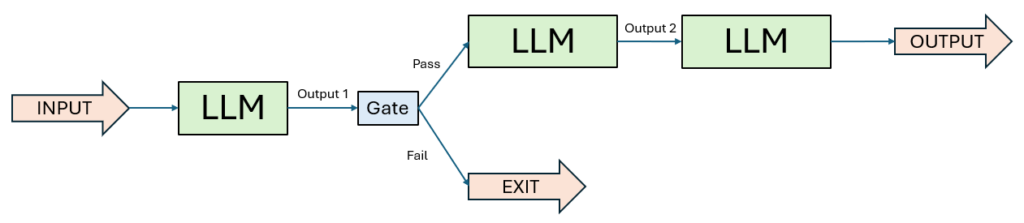
Was ich an diesem Ansatz besonders schätze, ist die Möglichkeit, kontrollierte Übergänge zwischen den Schritten zu schaffen. An definierten Zwischenpunkten lassen sich programmgesteuerte Prüfungen einbauen (sogenannte „Gates“), um sicherzustellen, dass der Prozess in die richtige Richtung läuft – und das Ganze nicht blind weiterläuft, wenn etwas schiefläuft.
Wann ist dieser Workflow sinnvoll:
Prompt Chaining ist ideal, wenn sich eine Aufgabe strukturiert in feste Teilaufgaben zerlegen lässt. Der Vorteil liegt in der Kombination aus besserer Steuerbarkeit und erhöhter Genauigkeit – auch wenn man dafür bewusst etwas mehr Rechenzeit in Kauf nimmt. Denn: Jeder Einzelschritt ist für das Modell einfacher und damit meist zuverlässiger zu bewältigen.
Beispiele, bei denen Prompt Chaining hilfreich ist:
- Generierung von Testfällen aus technischen Anforderungen für ECU-Software.
- Validierung technischer Spezifikationen gegen geltende Normen und Unternehmensstandards.
- Automatische Umwandlung von Simulationsdaten in zusammenfassende technische Berichte.
- Erstellung von Prüfplänen basierend auf CAD-Modellen und Komponentenfunktionen.
- Marketingtexte generieren und sie anschließend automatisiert in andere Sprachen übersetzen
- Eine Dokumentengliederung schreiben, diese mit bestimmten Kriterien abgleichen und erst danach den finalen Text auf dieser Grundlage erstellen
In der Realität zahlt sich dieser strukturierte Ansatz besonders bei inhaltlich dichten Aufgaben aus – vor allem, wenn Qualität wichtiger ist als Geschwindigkeit.
2. Workflow: Routing
In meiner täglichen Projektarbeit mit KI-Agenten hat sich Routing als unverzichtbares Muster bei komplexen Aufgabenstellungen erwiesen. Die Grundidee ist simpel, aber wirkungsvoll: Eine Eingabe wird klassifiziert und anschließend an eine spezialisierte Folgeaufgabe weitergeleitet.
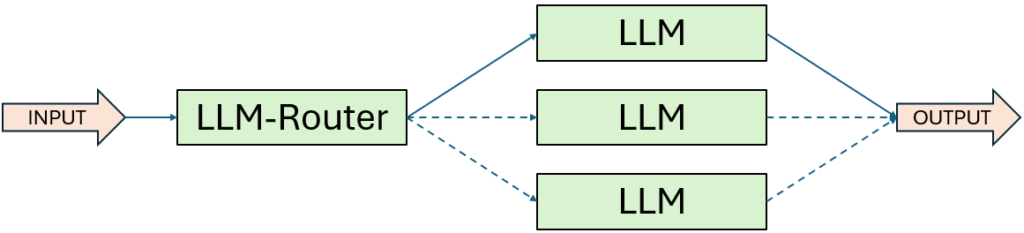
Dadurch kann man nicht nur unterschiedliche Problemtypen gezielt behandeln, sondern auch maßgeschneiderte Prompts und Prozesse für jede Kategorie definieren – was die Qualität der Ergebnisse deutlich verbessert. Ohne diese Trennung besteht die Gefahr, dass die Optimierung für einen bestimmten Eingabetyp die Leistung bei anderen Eingaben verschlechtert – ein typisches Risiko bei generalisierten Modellen.
Wann ist dieser Workflow sinnvoll:
Routing ist besonders dann sinnvoll, wenn es sich um vielschichtige Aufgaben mit klar unterscheidbaren Klassen oder Anfragetypen handelt. Die Klassifikation kann dabei entweder direkt durch das LLM erfolgen oder – je nach Genauigkeitsanforderung – durch ein vorgeschaltetes, regelbasiertes oder ML-basiertes Modell.
Beispiele, bei denen Routing hilfreich ist:
- Kundenanfragen automatisiert aufteilen, z. B. in allgemeine Fragen, Rückerstattungen oder technischen Support – jede mit eigenem Prozess, Prompt-Design und Toolset
- Zuweisung technischer Anforderungen an zuständige Fachbereiche (z. B. Mechanik, Elektrik, Software).
- Klassifikation eingehender Fehlermeldungen aus Test- und Validierungsumgebungen nach Fehlerursache.
- Automatische Weiterleitung von Change Requests an die jeweils betroffenen Module oder Systeme.
Routing ist für mich ein echtes Effizienz-Werkzeug – besonders bei skalierbaren Systemen mit vielen Eingabearten und stark variierenden Komplexitätsgraden.
3. Workflow: Parallelisierung
In vielen Engineering-nahen Projekten arbeite ich mit Aufgaben, die sich hervorragend parallelisieren lassen. Genau hier kommt der Parallelisierungs-Workflow ins Spiel. Dabei führen mehrere LLM-Instanzen gleichzeitig unterschiedliche Teilaufgaben aus – oder sie bearbeiten die gleiche Aufgabe auf unterschiedliche Weise. Die Ergebnisse werden anschließend programmatisch zusammengeführt.
Hier gibt es zwei bewährte Varianten:
- Voting: Dieselbe Aufgabe wird mehrfach durchlaufen, um verschiedene Perspektiven oder alternative Vorschläge zu erhalten. Die besten Ergebnisse werden dann ausgewählt oder kombiniert.
- Sectioning: Eine komplexe Aufgabe wird in unabhängige Teilaufgaben zerlegt, die parallel bearbeitet werden.
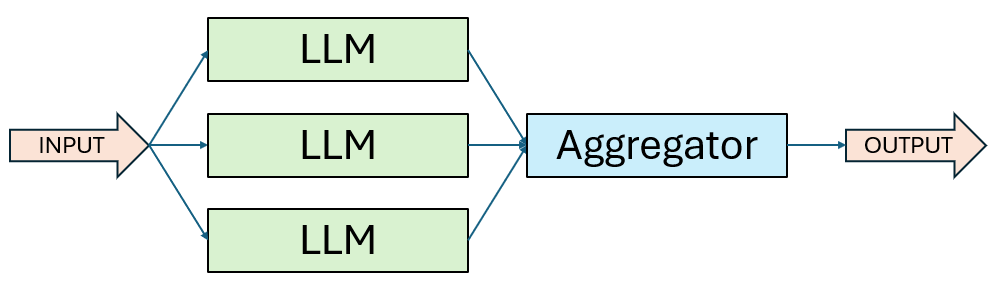
Wann ist dieser Workflow sinnvoll:
Parallelisierung lohnt sich immer dann, wenn Aufgaben entweder zeitkritisch sind oder mehrdimensionale Bewertungen erfordern. Besonders bei komplexen Themen mit mehreren Kriterien oder möglichen Lösungspfaden bringt es klare Vorteile, wenn sich das Modell gezielt auf je einen Aspekt pro Aufruf konzentrieren kann.
Beispiele, bei denen Routing hilfreich ist:
- Gleichzeitige Erzeugung von Artikeltiteln mit unterschiedlichen Tonalitäten (seriös, emotional, SEO-optimiert).
- Generierung personalisierter Werbetexte für unterschiedliche Zielgruppen gleichzeitig.
- Erstellung von Erklärungen auf verschiedenen Verständnisebenen (Grundschule, Mittelstufe, Uni).
- Mehrfachanalyse von Argumentationen, um Argumentationslücken oder Gegenpositionen aufzudecken.
Parallelisierung ist für mich ein echter Beschleuniger – besonders bei Tasks mit vielen Dimensionen oder wenn Ergebnisqualität durch Konsensbildung verbessert werden soll.
4. Workflow: Orchestrator-Worker
In besonders komplexen Projekten, in denen Aufgaben nicht im Voraus eindeutig zerlegt werden können, setze ich bevorzugt auf den Orchestrator-Worker-Workflow. Hier übernimmt ein zentrales LLM die Rolle des „Dirigenten“: Es analysiert die eingehende Aufgabenstellung, zerlegt sie dynamisch in passende Unteraufgaben, verteilt diese an spezialisierte Worker-Modelle – und führt die Ergebnisse anschließend wieder zusammen.
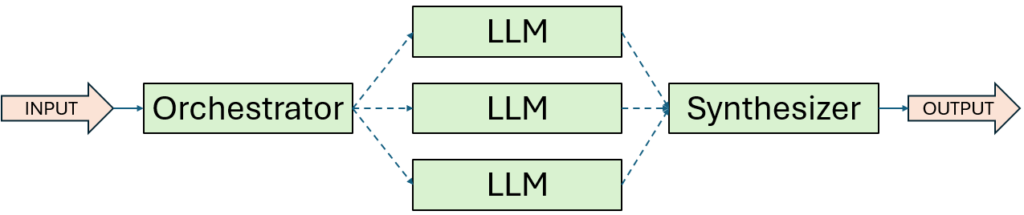
Im Unterschied zur klassischen Parallelisierung, bei der die Aufgabenteilung vorab definiert ist, zeichnet sich dieser Ansatz durch maximale Flexibilität aus: Die Struktur der Unteraufgaben entsteht erst zur Laufzeit, abhängig von den konkreten Eingabedaten.
Wann ich diesen Workflow einsetze:
Dieser Ansatz eignet sich hervorragend für Aufgaben, bei denen weder Anzahl noch Art der Schritte vorab vorhersehbar sind. Ein typisches Beispiel ist die Softwareentwicklung, wo sich erst während der Analyse zeigt, wie viele Dateien angepasst werden müssen und welche Arten von Änderungen erforderlich sind.
Beispiele, bei denen Orchestrator-Worker hilfreich sind:
- Coding-Agenten, die bei jeder Anfrage unterschiedliche Dateien modifizieren und eigenständig planen, wie sie vorgehen
- Rechercheaufgaben, bei denen Informationen aus verschiedensten Quellen gesammelt, gefiltert und zu einer fundierten Antwort zusammengeführt werden müssen
- Analyse von Änderungsanträgen mit Unteraufteilung in Auswirkungen auf Sicherheit, Produktion, Logistik und IT-Systeme.
Ich nutze diesen Workflow vor allem dann, wenn sich starre Prozesslogik nicht mehr sinnvoll abbilden lässt und das System ein hohes Maß an Eigenverantwortung übernehmen soll – aber trotzdem strukturiert und nachvollziehbar arbeiten muss.
5. Workflow: Evaluator-Optimizer
Immer dann, wenn Qualität oberste Priorität hat und eine schrittweise Verfeinerung echten Mehrwert bringt, setze ich gezielt den Evaluator-Optimizer-Workflow ein. Dabei arbeitet ein LLM als Generator, während ein zweites Modell als Evaluator fungiert – es bewertet die Ausgabe, gibt gezieltes Feedback und stößt gegebenenfalls einen weiteren Verbesserungszyklus an. Dieser Ablauf wiederholt sich in einer Schleife, bis ein zufriedenstellendes Ergebnis erreicht ist.
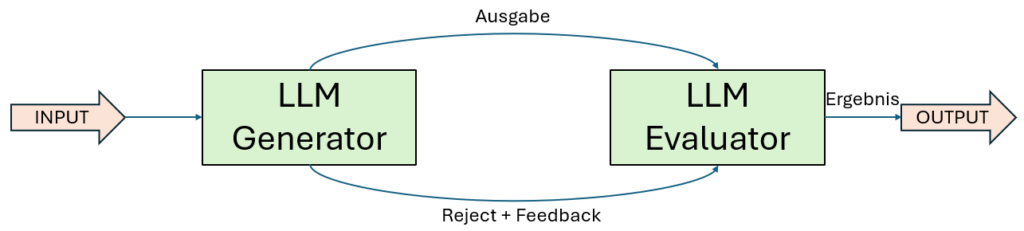
Der Nutzen dieses Workflows zeigt sich besonders deutlich, wenn zwei Bedingungen erfüllt sind:
- Modellantworten verbessern sich signifikant, sobald qualitatives Feedback formuliert wird,
- Das LLM selbst ist in der Lage, diese Bewertungen strukturiert zu geben – ähnlich wie ein Redakteur, der einen Entwurf überarbeitet.
Ich vergleiche diesen Workflow gerne mit dem Prozess eines erfahrenen Schreibers, der einen Text über mehrere Runden hinweg immer weiter schärft, bis er wirklich sitzt.
Wann ich diesen Workflow einsetze:
Der Evaluator-Optimizer ist besonders effektiv bei Aufgaben, bei denen klare Bewertungskriterien vorliegen und die Iteration systematisch zu besseren Ergebnissen führt. Vor allem in kreativen, sprachlich sensiblen oder datenanalytisch komplexen Bereichen liefert dieser Ansatz exzellente Resultate.
Beispiele, bei denen Orchestrator-Worker hilfreich sind:
- Literarische oder technische Übersetzungen, bei denen Nuancen, Fachbegriffe oder Stil erst im zweiten oder dritten Schritt vollständig getroffen werden
- Komplexe Rechercheaufgaben, bei denen ein Evaluator-Modell erkennt, ob noch relevante Informationsquellen fehlen – und den Suchprozess gezielt fortsetzt
- Verfeinerung von Simulationsbeschreibungen, um Verständlichkeit und technische Genauigkeit sicherzustellen.
- Schrittweise Optimierung von Konstruktionsvorschlägen anhand von Feedback zu Fertigbarkeit und Materialeinsatz.
- Evaluierung generierter Stücklisten auf Plausibilität, Variantenkonsistenz und Normkonformität.
Autonome Agenten – flexibel, leistungsfähig, aber mit Verantwortung
In den letzten Jahren habe ich den Reifeprozess von LLMs hautnah miterlebt – und damit auch den Aufstieg von Agenten in produktiven Anwendungen. Denn je besser die Modelle im Umgang mit komplexen Eingaben, im Planen, im Gründen und in der Toolnutzung werden, desto besser eignen sie sich als autonome, handlungsfähige Systeme im Unternehmen.
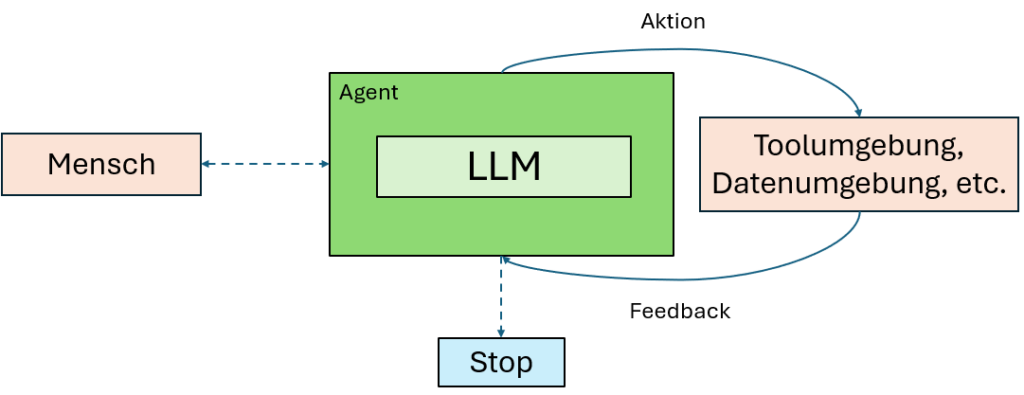
Ein Agent startet typischerweise mit einem Kommando oder einer Interaktion mit dem Menschen. Sobald das Ziel definiert ist, übernimmt er eigenständig: Er plant, führt aus und entscheidet, ob er für Rückfragen oder Einschätzungen erneut auf den Menschen zurückkommt.
Aus der Praxis weiß ich: Damit ein Agent zuverlässig arbeiten kann, braucht er in jedem Ausführungsschritt Zugriff auf sogenannte „Ground Truth“ – also reale Rückmeldungen aus der Umgebung, wie z. B. Tool-Ergebnisse, Systemantworten oder Code-Ausgaben. Diese Rückkopplung ist essenziell, damit der Agent seinen Fortschritt einschätzen und ggf. den nächsten Schritt anpassen kann. Bei Unsicherheiten oder an definierten Haltepunkten kann er pausieren und Feedback einholen.
Die Ausführung endet in der Regel, wenn das Ziel erreicht ist – oder wenn vordefinierte Stoppbedingungen greifen (z. B. eine maximale Anzahl von Iterationen). So stellen wir sicher, dass Autonomie nicht in Unkontrollierbarkeit umschlägt.
Was viele unterschätzen:
Trotz ihrer Fähigkeiten sind Agenten in der Umsetzung oft gar nicht so komplex. In den meisten Fällen handelt es sich schlicht um ein LLM, das in einer Schleife Tools nutzt und auf Rückmeldungen aus der Umgebung reagiert. Umso entscheidender ist es, dass die verfügbaren Tools klar strukturiert und sorgfältig dokumentiert sind – denn ein Agent ist nur so gut wie sein Werkzeugkasten.
Wann setze ich Agenten ein – und wann nicht?
Agenten sind die richtige Wahl bei offenen Problemstellungen, bei denen sich weder der Lösungsweg noch die Anzahl der Schritte im Vorfeld eindeutig bestimmen lassen. Sie entfalten ihr Potenzial besonders dann, wenn klassische „Wenn-dann-Logik“ an ihre Grenzen stößt.
Ich setze Agenten vor allem dort ein, wo das Modell in mehreren Zyklen arbeitet, sich kontinuierlich neu orientieren muss – und wo ich dem System ausreichend vertrauen kann, dass es selbstständig die richtigen Entscheidungen trifft.
Wichtig dabei:
Mit dieser Autonomie kommen nicht nur mehr Flexibilität, sondern auch höhere Komplexität, längere Laufzeiten und ein erhöhtes Fehlerrisiko. Deshalb empfehle ich – aus eigener Erfahrung – einen stufenweisen Rollout:
- Zuerst: ausgiebig in sandboxed Environments testen
- Parallel: geeignete Kontrollmechanismen und Sicherheitsgrenzen implementieren
- Dann: schrittweise in reale Prozesse überführen
Wer diese Schritte beachtet, kann mit Agenten Aufgaben automatisieren, die bislang als zu komplex oder zu variabel galten – und damit echte Produktivitätsgewinne erzielen.
Beispiele, bei denen Agenten hilfreich sind:
- Durchführung von FMEA-Voranalysen, bei denen das System automatisch Risiken erkennt und bewerten kann.
- Autonome Prüfung technischer Normenanforderungen und Zuordnung relevanter Passagen zu Entwicklungsobjekten.
- Im Test Bereich: Überwachung und Analyse von Sensordatenströmen mit automatischer Erkennung von Anomalien und Vorschlägen zur Ursachenanalyse.
Zusammenfassung und Fazit
In meinen Projekten mit KI-Agenten hat sich immer wieder gezeigt: Die besten Lösungen sind selten die komplexesten. Statt schwergewichtiger Frameworks überzeugen einfache, modulare und klar strukturierte Architekturen. Entscheidend ist, ob ein Anwendungsfall überhaupt ein agentisches System benötigt – oft reichen bereits gut optimierte Einzelabfragen mit Retrieval und Kontextbeispielen aus. Agenten lohnen sich vor allem dann, wenn Aufgaben variabel, unvorhersehbar oder stark kontextabhängig sind, während klassische Workflows ihre Stärken bei stabilen und klar strukturierten Prozessen ausspielen.
Frameworks wie LangGraph, Rivet oder Vellum können zwar den Einstieg erleichtern, bringen aber zusätzliche Abstraktionsschichten mit sich, die das Debugging erschweren und zur unnötigen Komplexität verleiten. Ich empfehle daher, wo immer möglich, direkt mit der API des Modells zu arbeiten – und Frameworks nur mit technischem Tiefenverständnis einzusetzen. Der technische Kern jedes leistungsfähigen Agentensystems ist das augmentierte LLM, also ein Sprachmodell mit angebundenen Tools, Memory und Zugriff auf externe Informationen via Retrieval.
In der Praxis haben sich fünf agentische Muster besonders bewährt:
- Prompt Chaining für sequentielle, gut strukturierte Aufgaben,
- Routing, wenn Eingaben kategorisiert und unterschiedlich verarbeitet werden müssen,
- Parallelisierung für zeitkritische oder mehrdimensionale Aufgaben,
- Orchestrator-Worker für dynamisch zerlegbare, komplexe Aufgaben, und
- Evaluator-Optimizer, wenn Feedbackschleifen die Ergebnisqualität signifikant steigern.
Autonome Agenten entfalten ihr volles Potenzial vor allem dort, wo der Lösungsweg nicht vorhersehbar ist. Sie planen, handeln und reagieren selbstständig – benötigen dafür aber eine robuste Tool-Infrastruktur, gute Rückkopplungspunkte („Ground Truth“) und klare Stoppkriterien. Richtig eingesetzt, ermöglichen sie die Automatisierung von Aufgaben, die bislang als zu komplex oder zu variabel galten – etwa in der Sicherheitsanalyse, Normprüfung oder sensorbasierten Testautomatisierung. Entscheidend bleibt: Agenten sind kein Selbstzweck, sondern ein Mittel zur Skalierung intelligenter, kontextgetriebener Prozesse – wenn man sie mit Bedacht einsetzt.
Recent Posts
Wie Großunternehmen Künstliche Intelligenz strukturiert in ihre IT-Landschaft einbinden – und dabei Kontrolle, Governance und Mehrwert sichern. Ausgangslage: Warum die Integration von KI kein...
Was bringt KI im Vertrieb wirklich – und wo?Eine umfassende Analyse von 71 wissenschaftlichen Studien zeigt: KI verändert nicht nur einzelne Tools, sondern greift entlang des gesamten...